ORIGAM 2018-1 Release Notes
We are happy to announce a new version of ORIGAM. It brings many visual, performance and productivity changes to the platform.
Breaking Changes
These are breaking changes introduced in this version:
Architect New Look
We worked on many productivity enhancements that make it easier and faster to work with your application’s model. This is what’s new in this version.
Editor Titles
Every editor now shows a big title (same like screens in the client interface) showing the title and the type of the currently edited element.
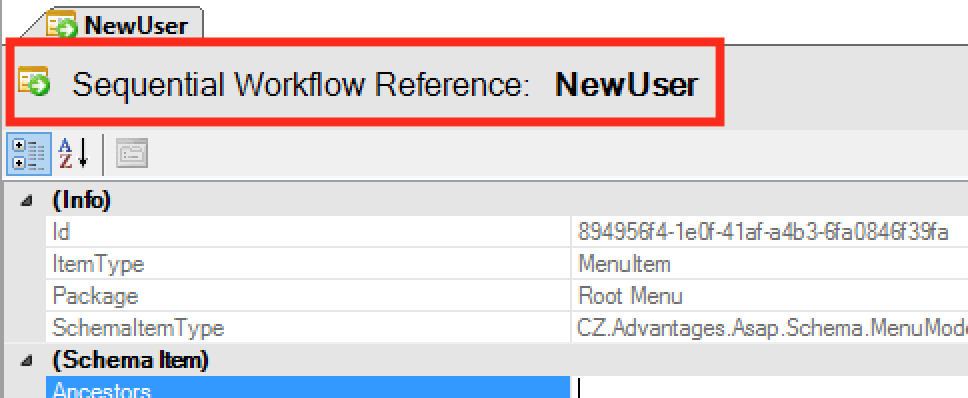
Property Grid Enhancements
Finally we added incremental search when picking links to other model elements.
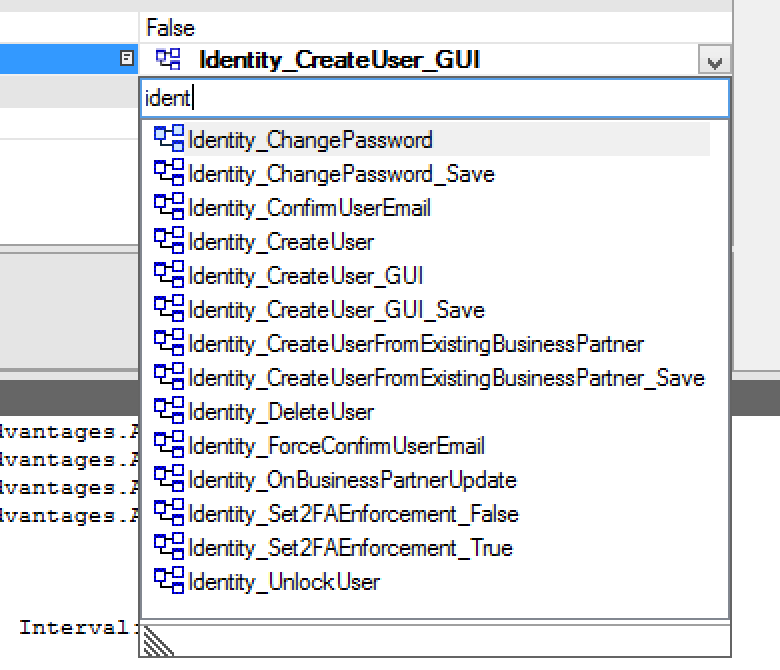
It is now also possible to navigate to target model element by clicking on the small ![]() icon next to the chosen element.
icon next to the chosen element.
Morover, to speed up creating new model elements we identified which property is typically edited first and we set it as default. E.g. when creating a new entity relationship, the default selected property now is Related Entity instead of Name.
Next Actions In Editors
Each editor now displays a list of all possible next actions on the right side panel.
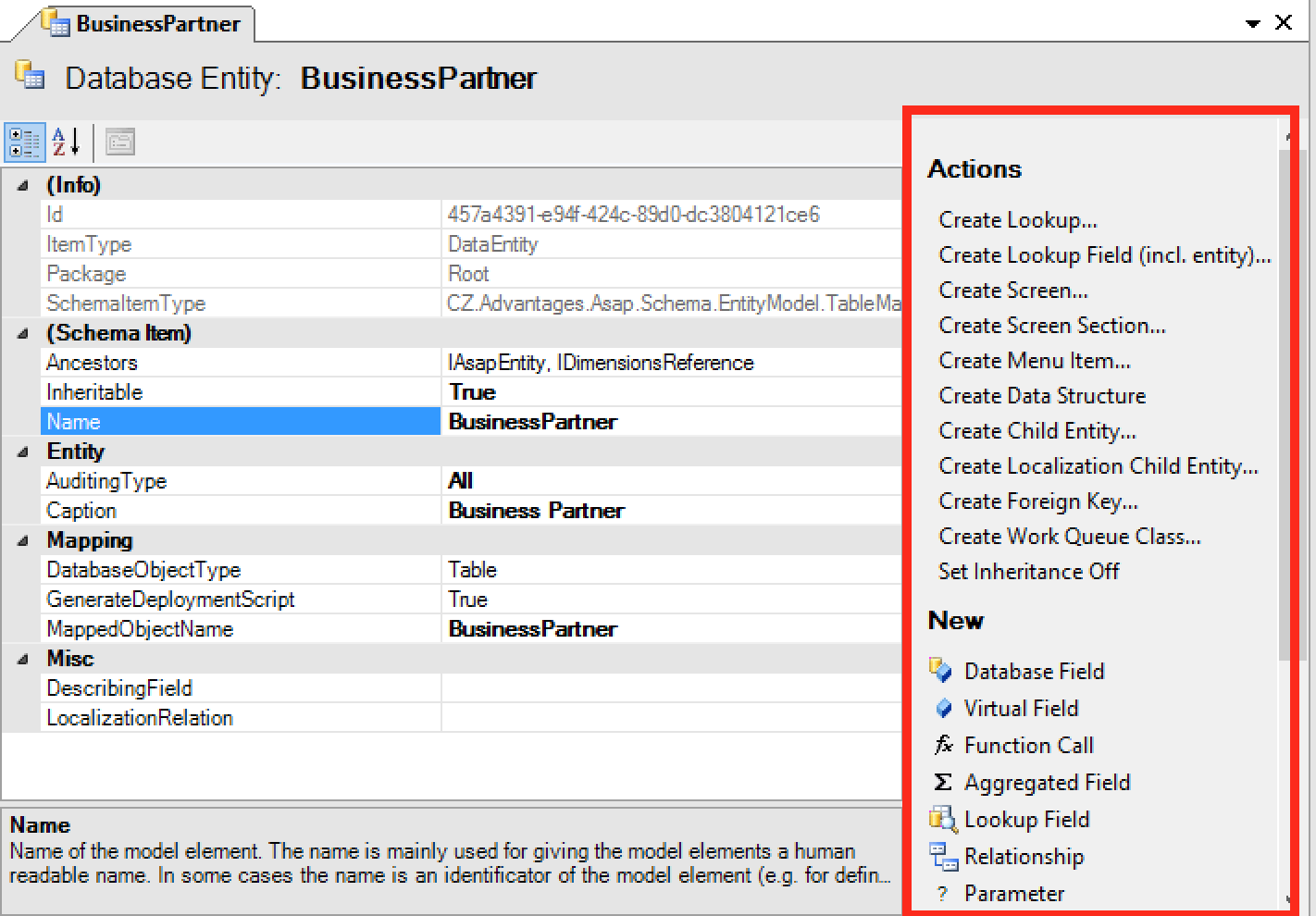
These are the same actions you would normally see in the New > and Actions > menus after right-clicking on a model element in the Model Browser. With one exception. When clicking on any New items, a pop-up dialog opens. This makes e.g. adding new entity fields much faster.
New Toolbar
Architect now has a brand new toolbar. The reasons why we have chosen this kind of a ribbon toolbar are:
- Allows showing screen’s action buttons
- Some editors now move their buttons to the toolbar (e.g. XSLT Editor)
- Unifies with web-client
- Displays labels which makes it easier to see what buttons do

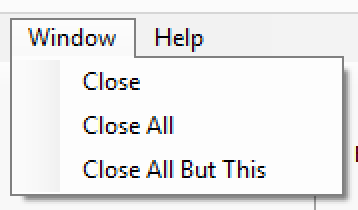
Window Menu
A new menu was added to handle common window actions, e.g. closing all tabs except of the current one.
Workflow Trace Screen
This screen is now finally sorted by date in descending order so you can immediately work with the latest traces.
SQL Console
A new type of editor was added that allows for executing SQL statements directly from Architect. Now you do not have to leave the environment if you want to quickly test your SQL statement. You can find it under Tools > SQL Console.
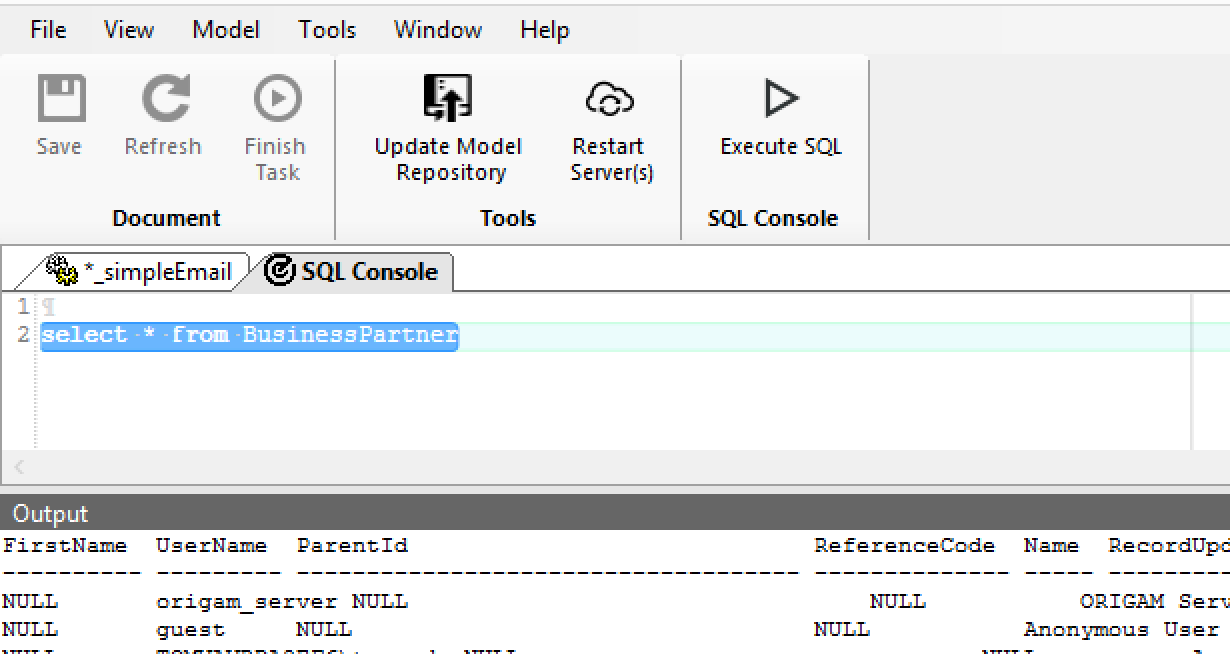
All SQL preview functions (e.g. displaying Data Structure’s generated SQL) were now moved to Actions > menu. When used, the resulting SQL is open in the SQL Console.
The generated SQL statements are now nicely indented for easier reading.

Deployment Script Generator
Deployment Script Generator now allows to generate scripts for altering columns (Filter: Different). E.g. if the column has a different data type or data length in a database. Just mark those differencies and ALTER TABLE ALTER COLUMN SQL statements will be created.
Model Actions Enhancements
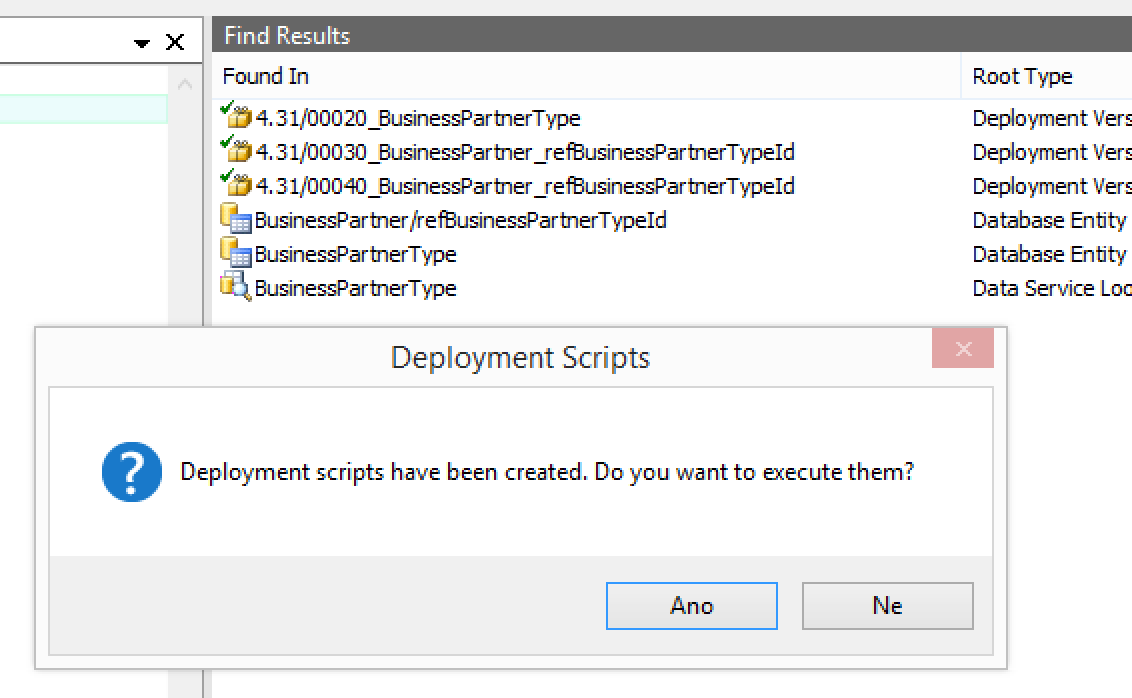
Overall actions are now more informative. When an action results in one or more model elements to be created, all those will be displayed in the Search Results pad.
When these are deployment scripts, you are even asked if you want to run them directly. This way, e.g. creating a lookup entity, is even faster.
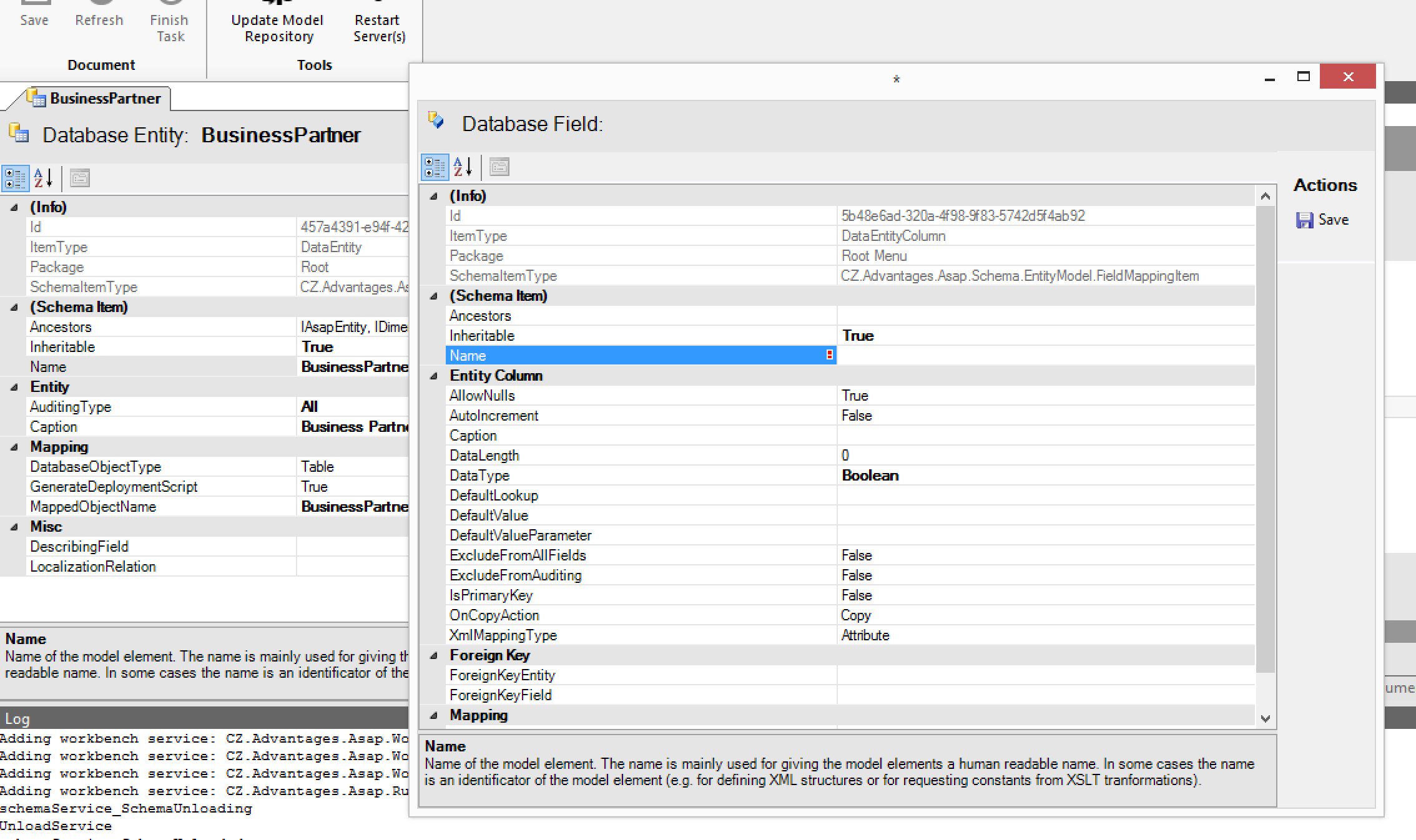
Create New Lookup Field (incl. Entity)
There are many improvements into this essential model action.
Firstly, after finishing the action the relevant deployment scripts are created for you. No need to go to the Deployment Script Wizard anymore (and you can also directly execute those scripts, see above).
Second, the functionality was enhanced. It is now possible to customize the resulting lookup (rename the Name field and it’s label). Now it is also possible to create a two-column lookup entity from this action. Whenever you need to create a code/name like entity you can do it straight from here including specifying the initial values (INSERT script will be created for you).
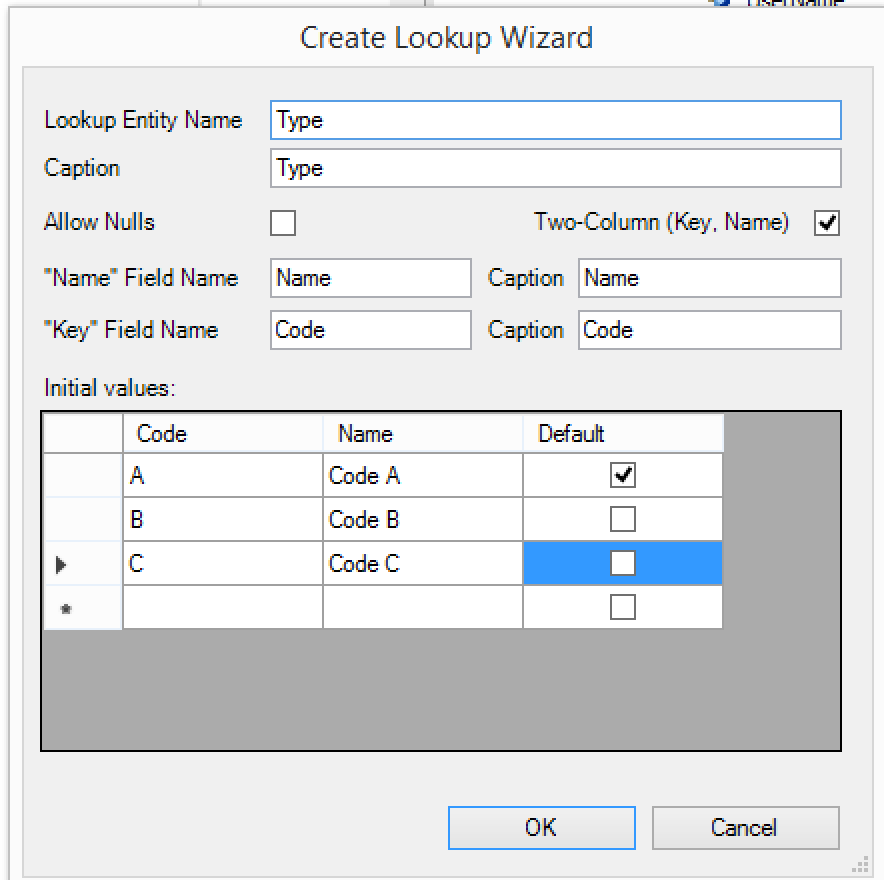
Additionally this wizard now automatically creates a unique index for the name field (and also code field, if two-column lookup is specified).
New Lookup Entity Based On a Field
Now it is also possible to run the above mentioned action when right-clicking on an entity field. It is then automatically two-column and the field you are staying at will be used as the foreign key.
Example: You already have an entity (e.g. Product) with an existing field “CategoryCode”, which is a 3 character string. If you right click on the Category field in model browser and select Create Lookup Field (incl. entity)… you will be able to enter the list of categories. You will call the new lookup entity ProductCategory. This entity will now have two fields - Code (it will automatically be the same type as your entity’s field - 3 characters string) and Name. Your original CategoryCode field will be also updated to be a foreign key to the new entity.
Troubleshooting Support
We dedicated this version to help admins troubleshoot various typical production issues.
Killing User Session (Web)
It is possible to “kill” a user session in a web client. This is sometimes needed if the user cannot close a screen because of an error or similar cases.
In order to support this just assign an existing OrigamOnlineUser screen. It has an action button which will kill the user’s session on any running web servers. After refreshing a browser the user will be presented with an empty environment - all open screens or workflows closed (without saving).
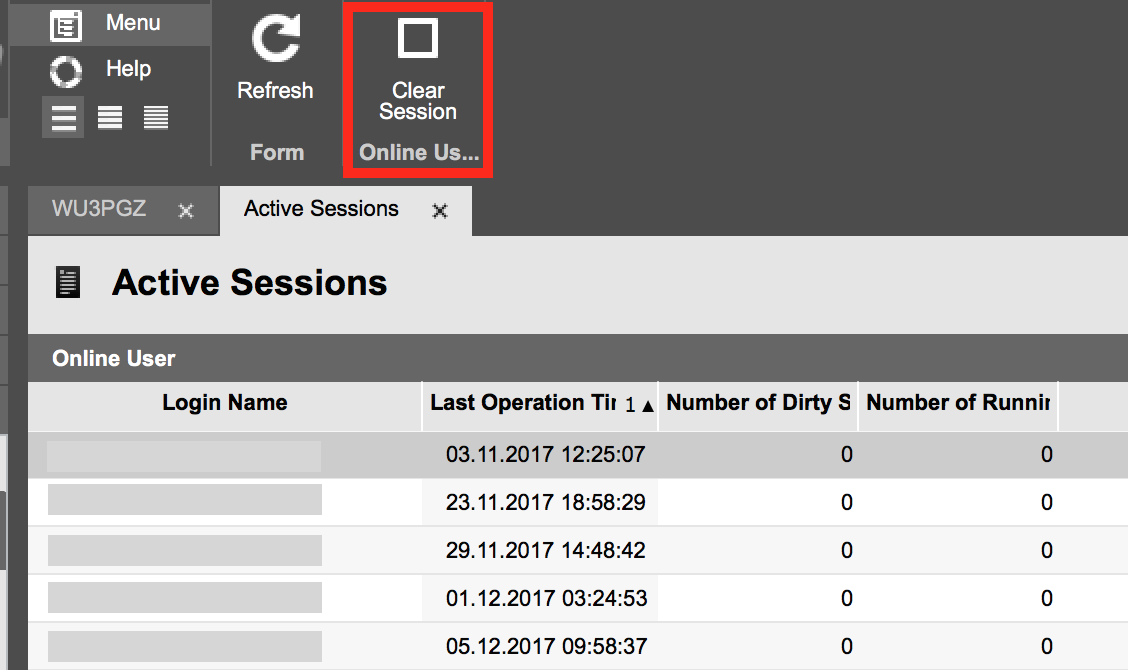
This screen has also some interesting information about the users - last operation time (opening a menu item or updating screen value are the watched operations here). You can also see how many screens the user has open.
Please note that these information are stored in a database and are not reset (we may include this feature in future versions). That means if the web server is restarted, these information stay. You should always look at the “Last Operation Time” to see the really active users.
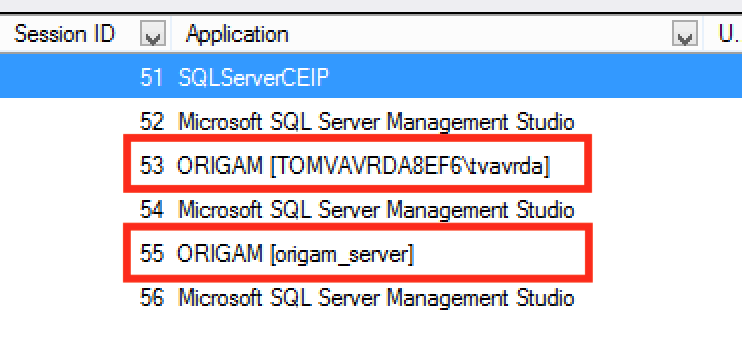
Showing User In SQL Server
Sometimes it would be important to see which application user is running the query showing in SQL Server’s activity monitor in order to identify who ran a blocking query. This is now possible. SQL Server Management Studio now shows “ORIGAM” + requesting users’s name in the Activity Monitor.
Disabling Workflow Tracing In Production Environment
It has been always a case that workflow tracing was useful when developing but in production environment it would produce massive amounts of data. We are introducing a new configuration flag that allows for disabling the tracing altogether on a specific instance. Just set this in AsapSettings.config (default is True):
<TraceEnabled>false<TraceEnabled>
Windows Desktop Client
Breaking Change - Reworked TEXT/NUMBER/DATE INput Box
In order to support free software we had to get rid of a closed-source text/date/number input box we have been using and instead we developed our own, open version. It should mostly worked the same way as the old version with an exception of a date input, which works slightly differently (but unified with Web client).
The new version for example allows short ways of entering dates. Suppose that we have May 2018:
- 1-2 digits (e.g. 17) - means a day in a current month and year. Will be expanded to 17.5.2018
- 4 digits (e.g. 1706) - means a day and month in a current year. Will be expanded to 17.6.2018
- 6 or 8 digits (e.g. 170619) - means a full date. Will be expanded to 17.6.2019
Support for Action Buttons
Desktop client now supports action buttons like the web client.
Please note that modal dialogs are not yet supported.
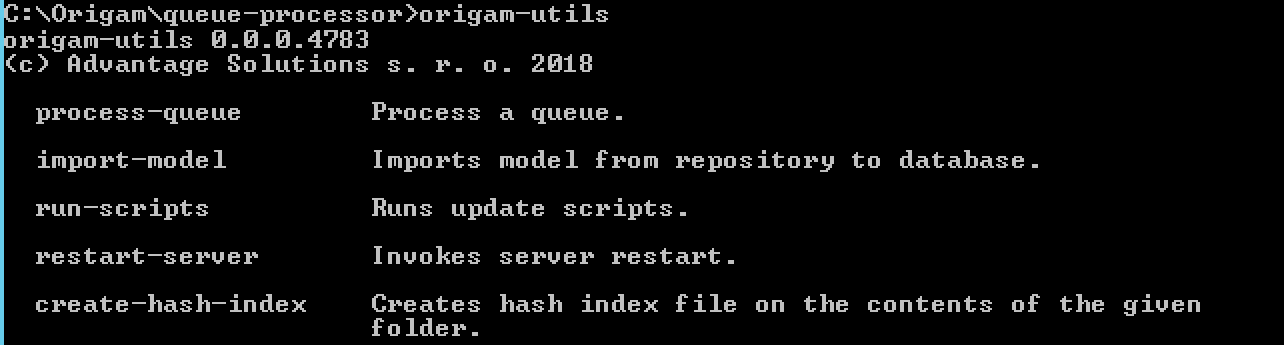
ORIGAM-Utils Console Application
We have developed a new console application that allows running some tasks from a console. There are two major groups of tasks available now:
- Deployment automation - These tasks support automated model deployment
- Work queue processing - it is possible to run auto-processing on a selected queue (even though this queue is not active). This allows for excluding a queue from normal auto-processing and running your processing from a console. This way you can also easily run multiple parallel auto-processing instances.
origam-utils works just like any other ORIGAM client application - must have all the binaries and configuration files available and connects to the database and model as usual.
In order to see all the available options just run origam-utils.exe.
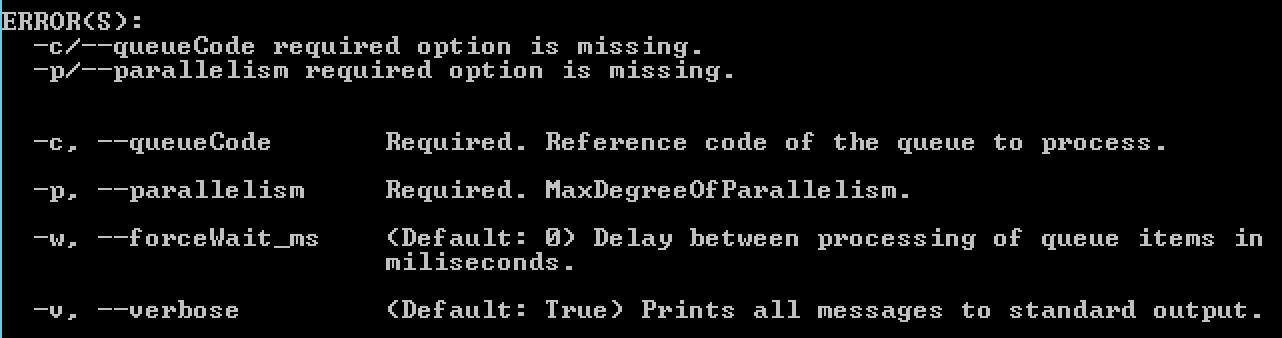
If you do not specify some parameters additional help will show up (e.g. when running origam-utils process-queue without specifying any additional parameters):
Model Changes
We enhanced the model language in various places to increase the possibilities of what you can achieve with ORIGAM.
Data Constant Model
It is now possible to override the data constant’s lookup in a data constant menu reference.
Entity Model
Auditing - added possibility to track only updates, skipping recording new row’s values. This is important for huge tables which, if audited fully, created enormous number of records in the audit log.
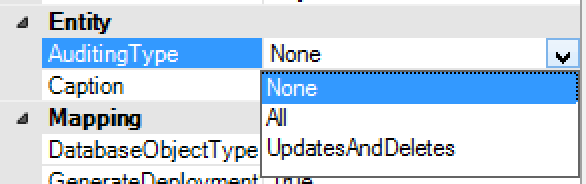
By specifying UpdatesAndDeletes option only those will be tracked. All is full audit including a copy of a new record.
Database Data Types Model
Before this version the only data types you could use in your entity model were forced by ORIGAM default mapping (e.g. String always resulted in NVARCHAR). From today you can register your own database-specific data types using this model.
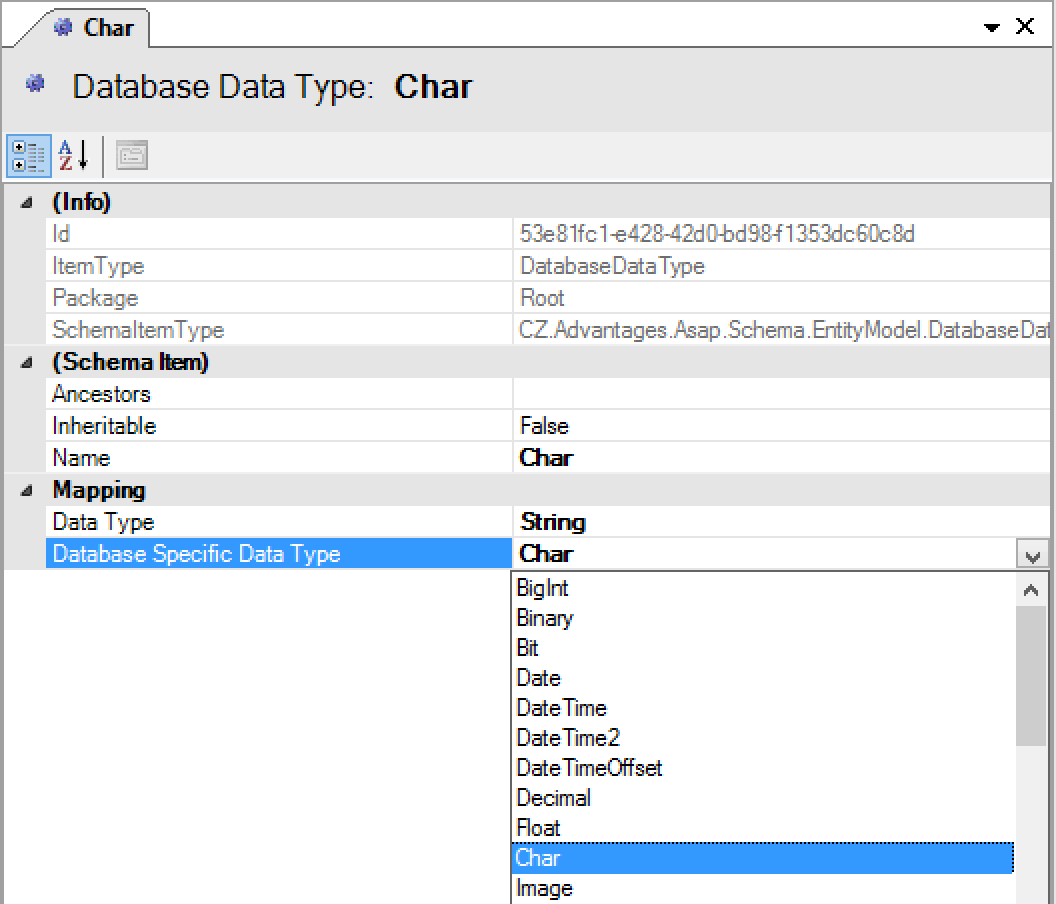
Just create a new Database Data Type in the Data Model, specify the ORIGAM data type (e.g. String) and SQL Server’s specific data type (e.g. Char).
When selecting String data type in the entity field you will be able to choose your Char specific data type in the Mapped Data Type property.
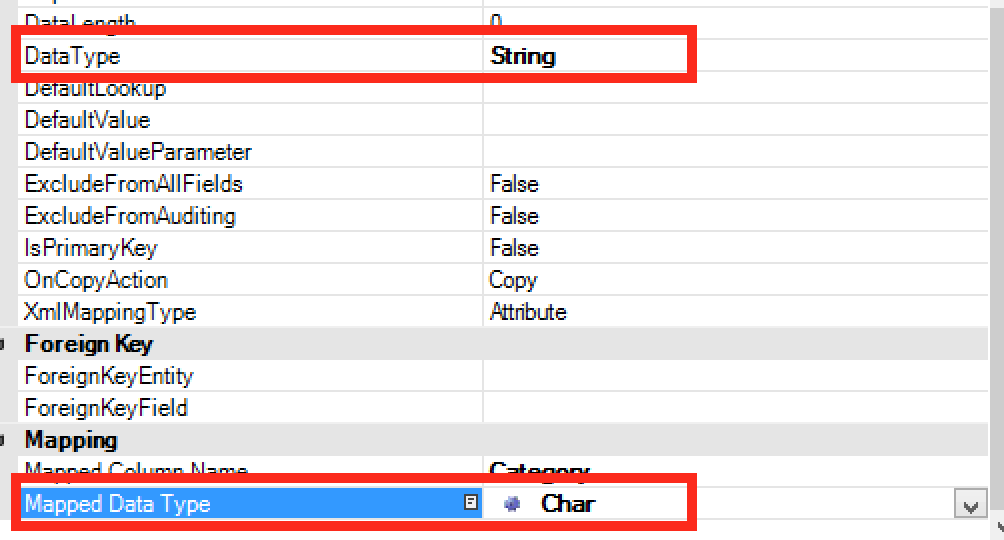
This data type will then be used in deployment scripts.
Data Structure MODEL
It is now possible to turn off concurrency check. Until now concurrency was checked for all database updates and deletes. A new property was added to DataStructureEntity > ConcurrencyHandling. The LastWins options turns off concurrency checks. When turned on, no error messages are shown when two users edit the same data concurrently. The last editor wins.
API MODEL
API/Page caching attributes added. It is now possible to specify MaxAge on an API page. If not specified, MaxAge=0, so the browser does not cache the data.
Menu Model
It is now possible to dynamically name the tabs in ORIGAM Client using Dynamic Form Label attributes.
When Dynamic Form Label Entity and Field are configured a value from this field will be used to name the tab. This also works as the user marks different rows in the screen. The selected row’s value will be used to name the tab.
(new) User Interface > Search Data Sources Model
This is a new model introduced in order to support searches in data using a search box in ORIGAM client. Before the search box was only used to search menu. Now, when user enters a phrase and presses Enter a search in data can be executed using this model.
Example: This search returns a list of bookings by a provided ticket number.
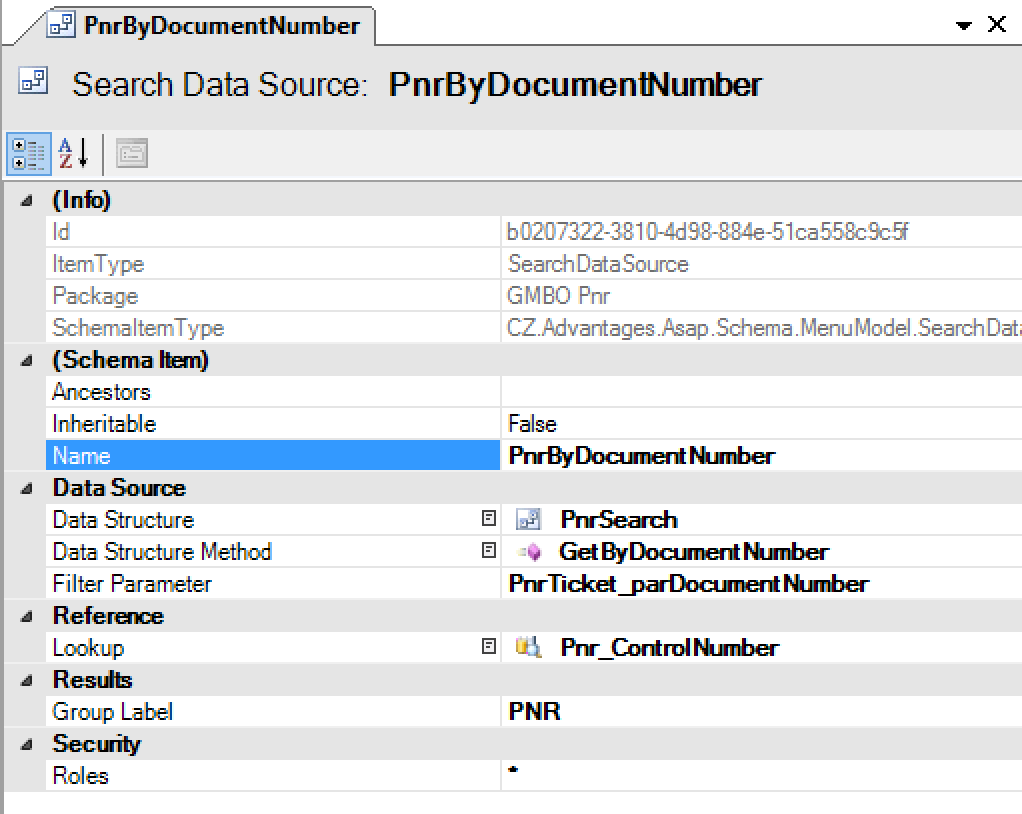
The value entered in the search box is passed to parameter specified in the Filter Paremeter attribute.
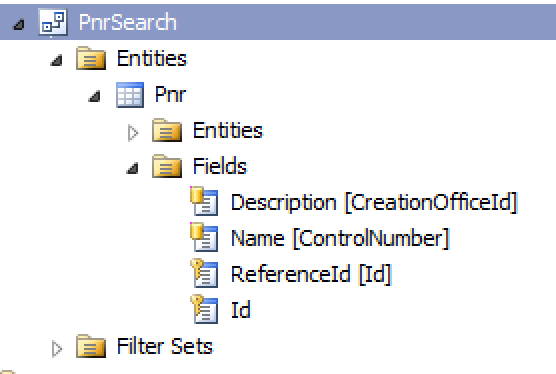
The data structure has to be crafted the way that it returns the following columns:
- Id (primary key)
- ReferenceId (an id of a found record - in our case Pnr.Id)
- Name (a text that will be displayed on a first bold line of the search result)
- Description (a text that will be displayed as a second line of the search result)
Example:
¨
Example search result:
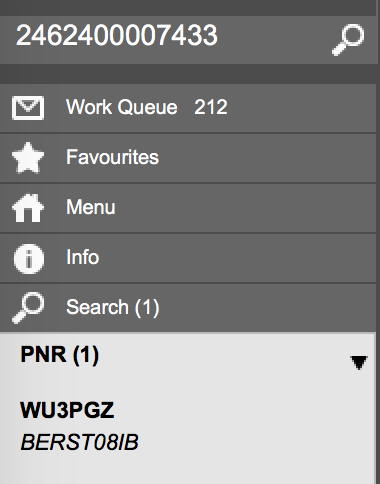
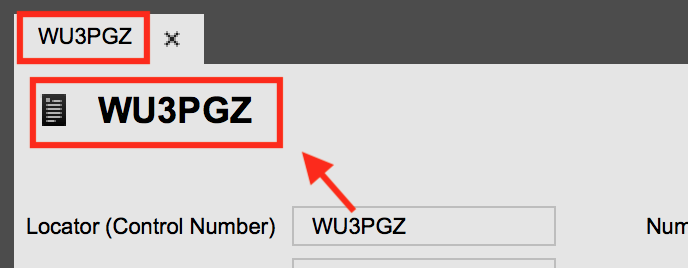
Using the Lookup attribute you assign a lookup which is then used to actually get a menu reference, like in a case of a standard lookup. Then it is used for opening a target menu item when user clicks on the search result. In our example it opens a PNR detail screen.
Workflows
FileSystemService.GetFileSystemInfo - Fills virtual entity FileSystemInfo with information on contents of given folder.
ExcelService - many bugs fixed.
ExcelReport -
CSV import - bugs fixed
If an external process returns an error through stderr, an exception is raised.
PrintService uses ghostscript instead of debenu now.
Data service now allows improving performance by sending commands to the database server in batches. Configurable via settings.UpdateBatchSize. It is also possible to mass load (insert) lots of rows into the database using bulk insert. It is much faster than usual inserts especially through low-latency connections. Configurable via settings.BulkInsertTreshold. If new records exceed this treshold a bulk copy will be used instead of a standard INSERT.
ExcelAgent.ReadSheet now allows to specify Culture for number fields (in order to parse e.g. decimal separators properly). Error messages improved if options are not provided or entity not found in the target data structure.
EDIFACT2XMLService
Queues
Work queue engine saw many changes in this release, mainly to support higher loads.
BREAKING CHANGE - Work Queue Automated Processing
This version changes a way how work queue items are picked up from the queue for automated processing.
Before, the queue processor loaded all the items from the queue and worked on them one by one. But this did not allow running multiple processors on a single queue in parallel. Queue processors would try to work on the same items.
Now the queue processor looks for the next unlocked message (internal method GetNextItem) and processes it.
Possible problems - One example is if a queue was created with the purpose of being worked on every 10 seconds without throwing away the message (the message would stay in the queue until next time) the queue will get stuck on this message forever, not even processing messages in other queues.
Example:
- Queue will start processing ExampleBadQueue
- It will ask for GetNextItem and get the item
- It will autoprocess workflows specified on this item
- Then it will ask for another item from the queue using GetNextItem method
- Since the last operation was not deleting the item from the queue, the message stayed there. The same message will get picked up.
- And processed again and again…
Before this scenario would work because the queue would load all items (one), process them and then move on to the next queue to work on it. After working all the queues it would come back to this queue again. Solution: ORIGAM Scheduler should be used to schedule running workflows periodically instead.
Another problem can occur when you do not use error queues to put away messages that ended up with an error after being processed automatically. In this case the queue will get filled up with error messages and queue processing will slow down dramatically. You should always configure an error queue when using automated processing.
Multiple Queue Processors
We implemented a possibility to support multiple queue processing engines in order to support a high volume of queues, each of which would receive a high amount of messages. In case of a single engine which would process all items in all queues it could take too much time cycling through all the work queues before returning back to the beginning. In the meantime too many messages would get created and the engine would just not catch up the high volume.
Now you can specify a Queue Processor in Work Queue Configuration (in Client).
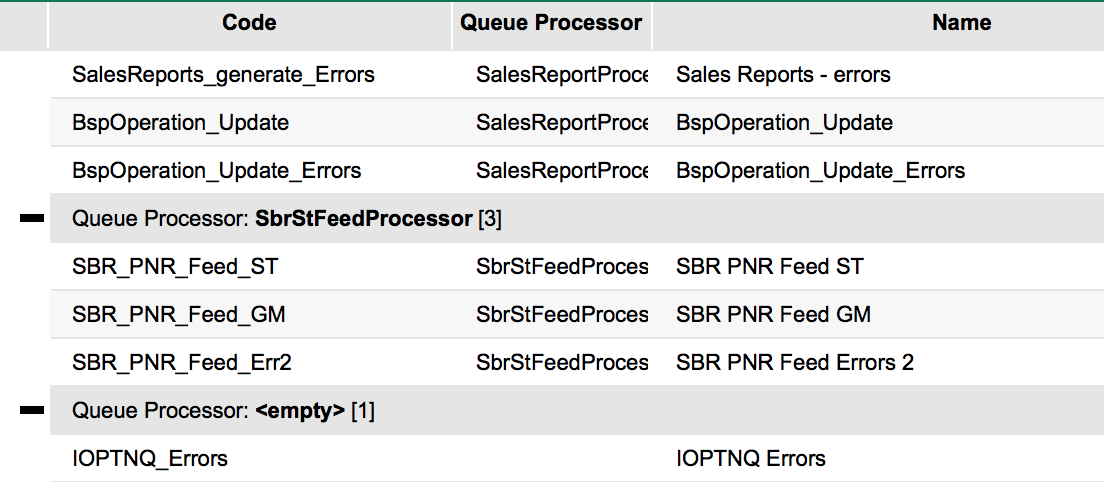
Only those ORIGAM instances (preferably ORIGAM Scheduler instances) will work on automatically processing a queue whose AsapSettings.config Name property is set to the same name as Queue Processor specified in Work Queue Configuration screen.
If Queue Processor is left empty (and multiple engines are set to auto-process queues) then all engines will process this queue in parallel.
Example: Multiple schedulers configured each to work on different set of work queues

New Loaders
WorkQueueWebSphereMQLoader - can process items from IBM MQ (client version 8.0.0.7).
WorkQueueIataBspFileLoader - can process items from airline BSP file formats
XSLT
New Xslt Editor Look
The XSLT editor interface was streamlined to get more space for your code. All settings were moved to the Settings tab and buttons for testing the transformation were moved to the new Architect toolbar.
Compiled XSLT Engine
A faster XSLT engine can now be used when creating XSLT transformations. It is set (by default) under the new Settings.
This engine is faster as it compiles the templates into native code before executing them. The engine can be set per-transformation. The old engine is used by all old transformations for compatibility reasons.
This update is also a preparation for introducing an XSLT 2.0 engine in future.
<xsl:param name="MyParameter" AS:DataType="Xml"/>
New XSLT Functions
AS:GetImageDimensions()
AS:LookupOrCreate - In one step they lookup a value and if not found they insert a new record to a database. For the insertion ListDataStructure is used, which has to have AllFields = True. Id is filled automatically (using a field specified in ListValueMember). The rest of the values are passed in the createParameters parameter the same way as extended parameters (i.e. list of ).
AS:ProcessMarkdown(string) function which consumes markdown text and returns an HTML
It is possible to set ‘User-Agent’ header when calling AS:HttpRequest function
Apply basic authentication if url of request contains a userinfo path (e.g. http://username:password@mysit.com/)
AS:Diff(string oldText, string newText) function which returns a list of changes (text)
DifferenceInSeconds
AS:DecodeSignedOverpunch
Crypto functions